Difference
Big-endian systems store the most significant byte of a word in the smallest address and the least significant byte is stored in the largest address.
Little-endian systems, in contrast, store the least significant byte in the smallest address.
Both forms of endianness are in widespread use in computing and networking.
Example
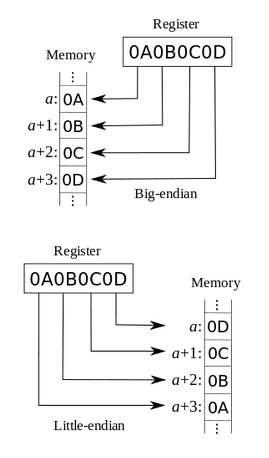
The data word “0A 0B 0C 0D” (a set of 4 bytes written out using left-to-right positional, hexadecimal notation) and the four memory locations with addresses a, a+1, a+2 and a+3.
In Big-endian systems, byte 0A is stored in a, 0B in a+1, 0C in a+2 and 0D in a+3. In Little-endian systems, the order is reversed with 0D stored in memory address a, 0C in a+1, 0B in a+2, and 0A in a+3.
Why ?
IBMs and Intel x86 are little endian, while Motorolas and Sun are big endian.
Big-endian is the most common convention in data networking (including IPv6), and little-endian is popular among microprocessors in part due to Intel.
Why is endianness so important? Suppose you are storing int values to a file, then you send the file to a machine which uses the opposite endianness and read in the value. You’ll run into problems because of endianness. You’ll read in reversed values that won’t make sense.
Endianness is also a big issue when sending numbers over the network. Again, if you send a value from a machine of one endianness to a machine of the opposite endianness, you’ll have problems. This is even worse over the network, because you might not be able to determine the endianness of the machine that sent you the data.
The solution is to send 4 byte quantities using network byte order which is arbitrarily picked to be one of the endianness (not sure if it’s big or little, but it’s one of them). If your machine has the same endianness as network byte order, then great, no change is needed. If not, then you must reverse the bytes.