Stats
Facebook has 1.5 billion monthly active users, 970 million daily active users as of June 2015.
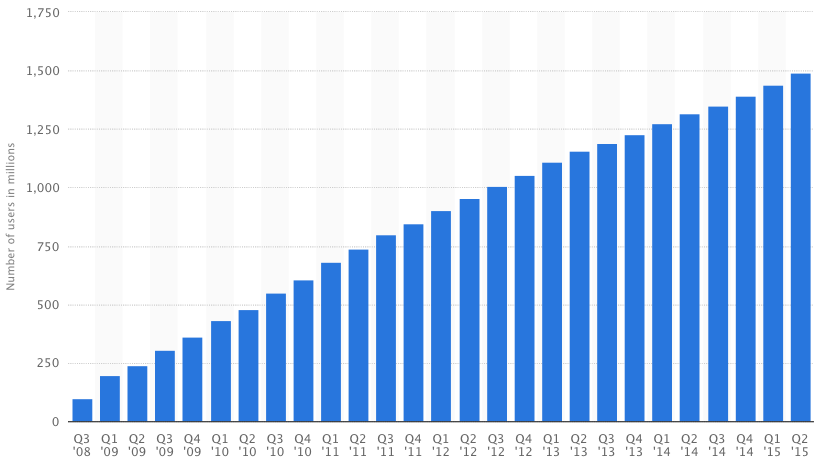
image from statista.com.
In 2009, Facebook stores 15 billion photos for the user, which grows at 220 million per week, and 550,000 per second at peak.
It’s 2015 now, you might want to mulitply these numbers by 3~6.
I have roughly estimated the statistics of Facebook users, Facebook photos and growth rate, just to give you an idea of the size of data Facebook has got:
Total user: 1.5b
Total photoes: 150b, which is 100 photo/user
Each photo got 4 different sizes, so 600b photos are stored.
New photo per day: 500m
New photo per second: 6,000
Peak incoming photo per second: 3m
Old architecture
3 tiers design:
Upload tier receives users’ photo uploads, scales the original images and saves them on the NFS storage tier.
Photo serving tier receives HTTP requests for photo images and serves them from the NFS storage tier.
NFS storage tier built on top of commercial storage appliances.
Network File System (NFS) is a distributed file system protocol originally developed by Sun Microsystems in 1984, allowing a user on a client computer to access files over a network much like local storage is accessed.
Problem
there is an enormous amount of metadata
… so much that is exceeds the caching abilities of the NFS storage tier, ** resulting in multiple I/O operations** per photo upload or read request
Solution
relies heavily on CDNs to serve photos.
Cachr: a caching server tier caching Facebook “profile” images.
NFS file handle cache - deployed on the photo serving tier eliminates some of the NFS storage tier metadata overhead
Haystack Photo Infrastructure
The new photo infrastructure merges the photo serving and storage tier into one physical tier. It implements a HTTP based photo server which stores photos in a generic object store called Haystack.
Goal: eliminate any unnecessary metadata overhead for photo read operations, so that each read I/O operation was only reading actual photo data
5 main functional layers:
HTTP server
Photo Store
Haystack Object Store
Filesystem
Storage
Storage
The commodity machine HW typically is 2x quadcore CPU + 32GB RAM + 512MB NV-RAM cache + 12TB SATA drives.
Non-volatile random-access memory (NVRAM) is random-access memory that retains its information when power is turned off (non-volatile).
This is in contrast to dynamic random-access memory (DRAM) and static random-access memory (SRAM)
So each storage blade is around 10TB. Configured as RAID-6 partition.
RAID 6, also known as double-parity RAID, uses two parity stripes on each disk. It allows for two disk failures within the RAID set before any data is lost.
Pros:
- adequate redundancy
- excellent read performance
- low storage cost down
Cons:
The poor write performance is partially mitigated by the RAID controller NVRAM write-back cache. Since the reads are mostly random, the NVRAM cache is fully reserved for writes.
The disk caches are disabled in order to guarantee data consistency in the event of a crash or a power loss.
Filesystem
How does filesystem read pictures?
Photo read requests result in read() system calls at known offsets in these files.
Each file in the filesystem is represented by a structure called an inode which contains a block map that maps the logical file offset to the physical block offset on the physical volume.
For large files, the block map can be quite large.
Problem
Block based filesystems maintain mappings for each logical block, and for large files, this information will not typically fit into the cached inode and is stored in indirect address blocks instead, which must be traversed in order to read the data for a file.
There can be several layers of indirection, so a single read could result in several I/Os (if not cached).
Solution
Extent based filesystems maintain mappings only for contiguous ranges of blocks (extents). A block map for a contiguous large file could consist of only one extent which would fit in the inode itself.
An extent is a contiguous area of storage reserved for a file in a file system, represented as a range. A file can consist of zero or more extents; one file fragment requires one extent. The direct benefit is in storing each range compactly as two numbers, instead of canonically storing every block number in the range.
Extent-based file systems can also eliminate most of the metadata overhead of large files that would traditionally be taken up by the block allocation tree… saving on storage space is pretty slight, but… the reduction in metadata is significant and reduces exposure to file system corruption as one bad sector in the block allocation tree causes much greater data loss than one bad sector in stored data.
Problem of Extent-based file systems
However, if the file is severely fragmented and its blocks are not contiguous on the underlying volume, its block map can grow large as well.
The solution
Fragmentation can be mitigated by aggressively allocating a large chunk of space whenever growing the physical file.
Currently, the filesystem of choice is XFS, an extent based filesystem providing efficient file preallocation.
XFS is a high-performance 64-bit journaling file system created by Silicon Graphics, Inc (SGI) in 1993.
…was ported to the Linux kernel in 2001. As of June 2014, XFS is supported by most Linux distributions, some of which use it as the default file system.
XFS enables extreme scalability of I/O threads, file system bandwidth, and size of files and of the file system itself when spanning multiple physical storage devices.
Space allocation is performed via extents with data structures stored in B+ trees, improving the overall performance of the file system, especially when handling large files.
Delayed allocation assists in the prevention of file system fragmentation; online defragmentation is also supported. A feature unique to XFS is the pre-allocation of I/O bandwidth at a pre-determined rate, which is suitable for many real-time applications.
Haystack
Haystack is a simple log structured (append-only) object store. Many images store in one Haystack. Typically, Haystack Store is 100GB size.
A Haystack consists of two files:
- haystack store file (containing the needles)
- superblock
- needles (1 needle is 1 image)
- an index file
1. haystack store file
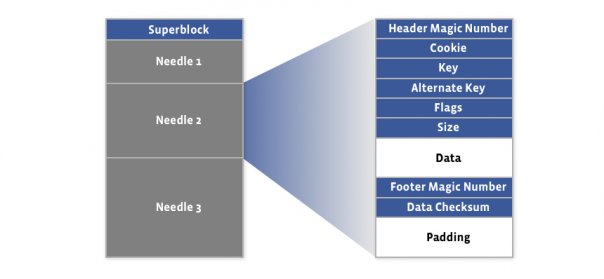
The first 8KB of the haystack store is occupied by the superblock.
following the superblock are needles
Needles represents the stored objects. Needle consisting of a header, the data, and a footer:

A needle is uniquely identified by its <Offset, Key, Alternate Key, Cookie> tuple.
Haystack doesn’t put any restriction on the values of the keys, and there can be needles with duplicate keys.
2. Index File
Needle consisting of a header, the data, and a footer:
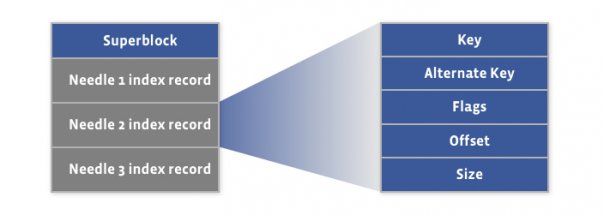
The index file provides the minimal metadata required to locate a particular needle in the haystack store file.

The index file is not critical, as it can be rebuilt from the haystack store file if required.
The main purpose of the index: quick loading of the needle metadata into memory without traversing the larger Haystack store file, since the index is usually less than 1% the size of the store file.
Summary
All needles are stored in Haystack store file, and their location information is stored in Index File.
What is Needle? Needles represents the stored objects (1 needle - 1 image).
Haystack Operations
write
append new needle to haystack store file.
later, corresponding index records are updated async.
In case of failure, any partial needles are discarded, and fix index from the end of the haystack.
You can’t overwrite any needle, but you can insert using same key. Later, the needle with dup keys but largest offset became the most recent one.
read
parameters passed in: offset, key, alt key, cookie, data size
if key, alt key and cookie matches, and checksum correct and needle is not marked as deleted, return.
delete
marks needle as deleted (set 1 bit), but index is not modified.
the deleted space is not reclaimed unless compact the haystack
Photo Store Server
Photo Store Server is responsible for accepting HTTP requests and translating them to the corresponding Haystack store operations.
In order to minimize the number of I/Os required to retrieve photos, the server keeps an in-memory index of all photo offsets.
At startup, the (photo) server reads the haystack index file and populates the in-memory index. The in-memory index is different from the index file in Haystack, as it stores lesser information, like this:

Photo Store Write/Modify Operation
- writes photos to the haystack
- updates the in-memory index
if there are duplicate images, the one stored at a larger offset is valid.
Photo Store Read Operation
passed in:
- haystack id
- a photo key,
- size
- cookie
The server performs a lookup in the in-memory index based on the photo key and retrieves the offset of the needle containing the requested image.
Since haystack delete operation doesn’t update the haystack index file record. Therefore a freshly populated in-memory index can contain stale entries for the previously deleted photos. Read such photo will fail and the in-memory index is updated to 0.
Photo Store Delete Operation
After calling the haystack delete operation, the in-memory index is updated to ‘offset = zero’
Compaction
Compaction is an online operation which reclaims the space used by the deleted and duplicate needles.
creates a new haystack
HTTP Server
evhttp server
multiple threads, with each serving a single HTTP request. Workload is mostly I/O bound, thus the performance of the HTTP server is not critical.
Summary
Storing photos as needles in the haystack eliminates the metadata overhead by aggregating hundreds of thousands of images in a single haystack store file.
This keeps the metadata overhead very small and allows us to store each needle’s location in the store file in an in-memory index.
This allows retrieval of an image’s data in a minimal number of I/O operations, eliminating all unnecessary metadata overhead.